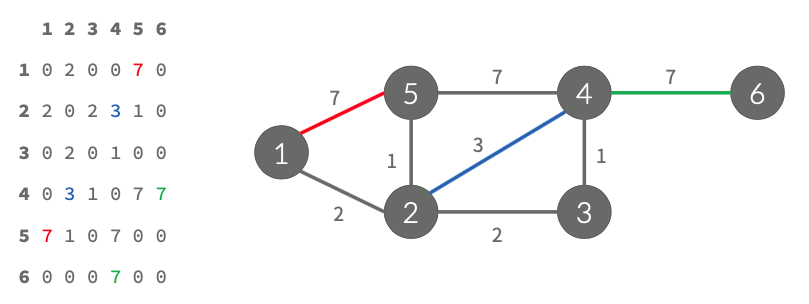
개요Trie란?LeetCode 208번 문제 - Implement Trie (Prefix Tree) 1. Trie란?문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료 구조이다.Trie라고 적고 try로 발음되며, 다른 말로는 래딕스 트리(Radix Tree), 접두사 트리(Prefix Tree), 또는 탐색 트리(Retrieval Tree)라고도 한다. 우리가 검색할 때 볼 수 있는 자동완성 기능, 사전 검색 등 문자열을 탐색하는데 특화된 자료구조이며,디테일한 설명은 박지훈님이 작성한 [자료구조] 트라이(Trie)를 참고하자. [자료구조] 트라이 (Trie)트라이(Trie)는 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조이다.우리가 검색할 때 볼 수 있는 자동완성 기능,..