목차
- Redis는 안써봐서 모르겠어요
- RDBMS vs NoSQL
- MySQL vs Redis
- 스키마
- 확장성
- 트랜잭션
- Redis의 특징
- 디스크 X , 인메모리 O = 빠름
- 싱글 스레드
- 고가용성 (automatic fail over)
- 기타
- 참고 자료
1. Redis는 안써봐서 모르겠어요
2024년 한 해 동안 개발자 친구들과 얘기하면서 지식을 공유할 때, 빈번하게 사용됐던 문장은 위의 소제목이 아닐까 싶습니다.
현업에서는 MySQL만을 사용하다보니, 개인적으로는 NoSQL에 대한 경험이 전무한 상황이었습니다.
이로 인해 아래와 같은 대화가 나눠진 적이 있었습니다.
🙋🏻♀️ 어드민에서는 DB 테이블에서 extraData라는 컬럼을 하나 만들어두고, 그 안에 json 형식으로 key - value를 저장하고 -> 데이터를 역직렬화해서 가져온 다음 -> 데이터 파싱 후 변경 내용 업데이트 -> 데이터를 직렬화 해서 다시 저장하는 로직을 사용하고 있어요.
🙋🏻♀️ 아무래도 DB 테이블에 컬럼 하나를 추가 / 삭제하는 과정에서도 DBA 담당자분의 협의를 거쳐야하니, 자주 사용되지 않는 컬럼을 추가하고 삭제하거나 매번 새로운 테이블을 생성하기 보다는 위와 같인 방식을 사용하는게 이해는 돼요.
🙋🏻♀️ 그런데 매번 try - catch로 파싱 에러를 잡고, json을 직렬화 <-> 역직렬화 하는게 최선일까 생각이 들었어요.
🙋🏻♀️ 제가 겪은 어드민에서는 extraData안에 key값을 수십 여가지로 저장한 경우도 있었는데, 이때 사용되는 key의 개수는 안타깝게도 나날이 증가하고 있었어요. 어드민은 트래픽을 고려하는 서비스가 아니니 이렇게 작업해도 무방하겠지만, 이렇게 점점 extraData가 비대해지는게 최선일까 싶었어요. 한편으로는 만약 트래픽이 발생하는 서비스에서 어떤 상황이 발생할 수 있을지 궁금해졌어요.
🙋🏻♀️ (1) 역직렬화 <-> 직렬화 하는 과정에서 안정성이 떨어짐 (ex : 존재하지 않는 key 값으로 파싱)
(2) 너무 많은 key를 역직렬화 <-> 직렬화 하는 과정에서 thread가 반환되기까지 오래 걸림
-> 해당 API의 호출량이 많다면 thread-pool 고갈 우려
-> 비즈니스 로직이 복잡해질수록 해당 API에서 Timeout Exception이 발생할수도 있지 않을까?
(3) 이 과정에서 어쩌면 동시성 이슈 우려
-> Lock을 잘 걸어주면 되겠지만, 직렬화 <-> 역직렬화 과정이 오래걸리면 Lock을 풀기까지 시간이 걸리지 않을까?
-> 트랜잭션의 격리 수준 (Isolation Level)을 변경하는 것도 Lock과 마찬가지로 격리 수준 해제까지 오래걸릴수도 있을것 같은데
🙋🏻♂️ 어? 그거 Redis를 쓰면 굳이 json 데이터를 일일이 파싱하지 않아도 돼요.
🙋🏻♂️ Redis에서는 필요한 key에 해당하는 value만 가져오니 안정성 이슈나 Timeout을 걱정할 필요는 없고, 기본적으로 싱글 스레드 구조다보니 동시성 이슈를 크리티컬하게 고민하는 경우는 드물어요.
🤷🏻♀️ 공유 감사해요! 그런데 Redis는 안써봐서 잘 모르겠네요. 안써봐서 모른다고 대답을 하니, 직접 공부를 해보면 되지 않을까 싶었습니다.
그래서 회사 친구들과 개발자를 위한 레디스를 스터디 주제로 다루게 되었습니다. (스터디는 2024년 12월 말 부터 시작되었으며, 현재 진행형입니다.)
NHN Cloud 출신의 김가림 선배님께서 출판하신 책으로, DBA가 아닌 개발자의 입장에서도 이해하기 쉽게 서술되어서 Redis에 대해 이해하는데 큰 도움이 되었습니다.
해당 책은 2023년 11월에 출판되었으며, 후술되는 Redis의 정리 내용 또한 2023년에 업로드된 공식 문서의 내용을 참고하여 작성된 점을 공유드립니다.
아울러 현재 보고계신 글은 해당 책의 챕터 1 ~ 챕터 4까지 내용을 포함하며, 해당 챕터들은 Redis의 기본 개념과 유즈 케이스에 대한 원초적인 지식을 다룹니다.
때문에 Redis의 개념이 익숙하신 분은 굳이 정독하지 않아도 무방합니다.
참고로 Redis 쿼리는 직접 Reids를 설치하지 않아도 Redis 온라인 에디터를 통해 체험이 가능합니다.
2. RDBMS vs NoSQL
구글링이나 ChatGPT를 통해 RDBMS와 NoSQL의 특징을 물어보면 보통 아래와 같은 내용을 볼 수 있습니다.

이렇게 검색해서 얻는 데이터는 고개는 몇 번 끄덕이지만 뒤돌아서면 머릿속에 오래 남지 않는다는 느낌을 받았습니다.
때문에 위의 내용을 전부 다루기보다는 인상 깊은 몇 가지 특징만 다루도록 하겠습니다.
책에서 언급된 예시 코드와 함께 스키마, 확장성, 트랜잭션을 관점으로 아래에 서술될 3. MySQL vs Redis에서 다뤄보도록 하겠습니다.
본래라면 Redis의 특징 및 장단점을 먼저 서술해야겠지만,
개발자에게는 말 보다는 코드로 보는 이해가 더 명확하지 않을까 싶은 마음에
코드로 설명하는 Redis를 먼저 서술하도록 하겠습니다.
보다 다양한 내용을 좀 더 디테일하게 서술하고 싶었으나, TL;DR을 방지하고자 핵심만 기술한 점 양해 부탁드립니다 😅
(TL;DR : Too Long, Didn't Read)
3. MySQL vs Redis
(1) 스키마
MySQL은 고정된 스키마를 사용합니다. 때문에 초기 테이블 셋팅시 테이블 구조(컬럼 이름, 데이터 타입 등)를 명시적으로 정의하게 됩니다.
CREATE TABLE users (
id INT AUTO\_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL
); 만약 정의된 테이블 구조대로 데이터를 조작하지 않을 경우, 에러가 발생하거나 예상치 못한 데이터가 저장될 수도 있습니다.
반면 Redis는 스키마가 없는 key-value 구조의 NoSQL(Not Only SQL)입니다.
때문에 데이터를 저장하기 전에 구조를 저장할 필요가 없습니다.
SET user "johndoe"
GET user # johndoe
SET user 123
GET user # 123 보다시피 변화무쌍하게 스키마를 변경할 수 있습니다. Redis에서는 숫자 데이터를 저장할 때 문자열로 저장이 되지만, 내부적으로 자동으로 숫자로 해석하고 처리가 가능합니다.
SET my_number 123
INCR my_number
GET my_number # 124 이렇게 저장된 key값들은 KEYS 또는 SCAN을 통해 조회가 가능합니다.
SET key1 value1
SET key2 value2
SET user:1 john
SET user:2 jane
KEYS * # key-value 전체 출력
SCAN 0 # Key-value 전체 출력 단, KEYS는 모든 키를 조회하며, 이는 싱글 스레드 인 redis의 특성상 굉장히 오래걸리고 위험한 커맨드입니다.
(싱글 스레드의 구조는 4. Redis의 특징 - 싱글 스레드에서 후술하도록 하겠습니다.)
해당 커맨드가 실행되는 동안 모든 GET SET 커맨드는 수행되지 않고 대기상태로 머물기 때문입니다.
데이터가 얼마 없는 상태에서는 KEYS를 사용해도 무방하지만, 그렇지 않은 환경에서는 서비스에 크리티컬한 임팩트를 줄 수 있습니다.
반면 SCAN은 cursor 값을 0으로 줌으로써 한 번에 모든 데이터를 조회하는 것이 아닌 일괄 처리(Paginated)로 반복 호출을 통해 조회하므로, 서버의 부하를 줄일 수 있습니다.
때문에 key값을 조회할때는 KEYS가 아닌 SCAN을 통해 조회하는 것이 안전합니다.
물론 SCAN 역시 cursor를 기반으로 동작이 되다보니, 시간복잡도는 O(N)에 수렴하므로 저장된 key의 개수가 많을 수록 성능이 저하된다는 단점 역시 존재합니다.
때문에 SCAN을 사용할때도 범위를 적절히 조율하는 점도 중요합니다.
반대로 key를 삭제하는 커맨드는 다음과 같습니다.
SET key1 value1
SET key2 value2
SET key3 value3
SET key4 value4
# 여러 키 삭제 (단일 삭제도 가능)
DEL key1 key2
# 출력: (integer) 2
# 없는 키 삭제
DEL non\_existent\_key
# 출력: (integer) 0
# DB에서 즉시 삭제하지 않고 백그라운드에서 비동기로 삭제
UNLINK key3 key4
# 출력: (integer) 2 DEL의 경우, 삭제할 키 N개를 찾기 위해 시간복잡도 O(N) 이 필요됩니다.
그러나 UNLINK의 경우, 삭제할 키의 개수와 관계 없이 O(1) 의 시간 복잡도를 가집니다.
때문에 성능을 고려하면 가급적 DEL보다는 UNLINK의 사용을 권장합니다.
Redis의 스키마와 관련한 일부 커멘드를 간략히 소개했습니다만, 도입부에 언급했듯이,
스키마가 없는 변화무쌍한 NoSQL이므로 RDB에서 밥먹듯이 쓰이는 조인(JOIN)의 개념이 의미가 없다는 특징도 존재합니다.
Redis 자체에서는 JOIN 연산을 직접 지원하지는 않지만, 원할 경우 여러 key - value를 조합하여 JOIN과 유사한 기능을 구현할 수는 있습니다.
다만 JOIN이 중요한 로직의 경우, NoSQL보다는 스키마가 명확한 RDB에서 사용하는 것이 보편적으로 권장됩니다.
(2) 확장성
RDB인 MySQL에서는 서버를 여러대로 수평적 확장하기보다는 서버 자체의 성능을 높이는 수직정 확장을 권장합니다.
Replication(Master <-> Slave 구조) 로 수평 확장을 하면 읽기와 쓰기의 역할을 분리하여 성능 개선에 도움을 줄 수는 있지만,
쓰기 요청은 오직 Master에서만 가능하다는 특징이 있습니다.샤딩(Shard Key를 기준으로 데이터를 나누어 DB에 분산해서 저장) 을 통해 여러개의 DB에 분산해서 저장이 가능하지만,
샤딩 키의 분배를 고려해야하며, 특정 데이터에 대한 요청이 몰릴 경우 해당 샤드에만 트래픽이 몰리는 핫 스팟 현상이 발생할 수 있습니다.
반면 NoSQL인 Redis는 클러스터 구조를 통해 데이터를 여러 노드에 분산 저장할 수 있습니다.
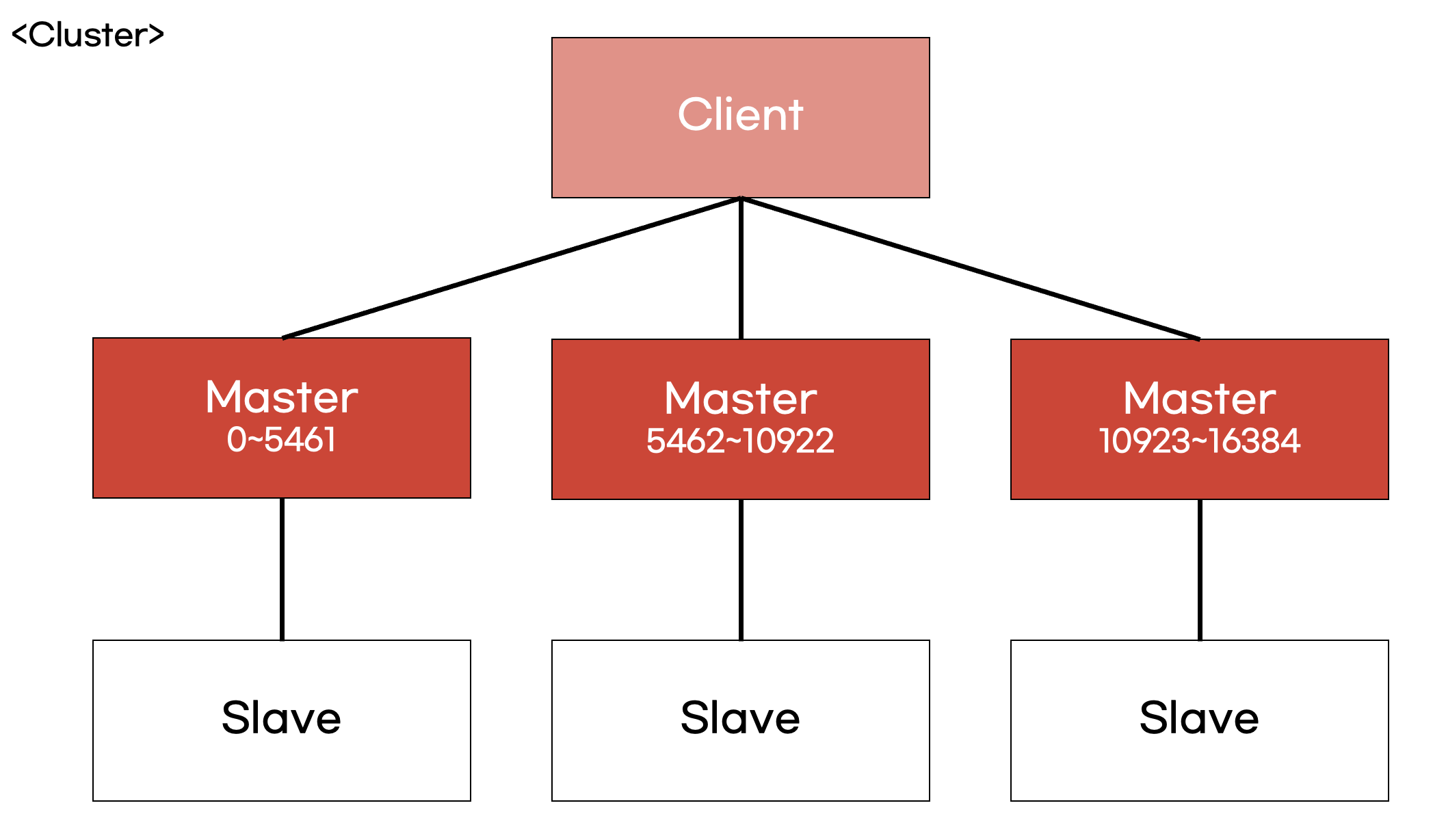
클러스터 구조는 데이터를 여러 개의 Master 노드에 샤딩(분산 저장) 하는 기법으로, 각 Master 노드는 자체적인 Slave 노드 역시 가지고 있는 구조입니다.
이에따라 쓰기와 읽기 부하를 모두 분산하는 구조로 구성이 가능합니다.
클러스터 구조에서는 굳이 샤딩을 구현하지 않아도, 클라이언트가 특정 키를 해싱하여 적절한 노드에 요청을 보내는 방식이 이루어집니다.
또한 싱글 스레드 구조인 Redis의 특징상, 스케일 업을 통해 더 빠른 CPU, 더 많은 RAM을 적용하더라도 성능 상의 한계가 존재합니다.
때문에 Redis는 확장성 측면에서는 스케일 아웃이 적합합니다.
(3) 트랜잭션
MySQL은 트랜잭션을 지원합니다. 단, 트랜잭션의 특징상 물리적으로 같은 DB에 존재하는 데이터들을 함께 조작한다는 전제하에 트랜잭션을 지원합니다.
만약 다른 서로 다른 DB의 트랜잭션을 지원하고 싶다면 별도로 분산 트랜잭션을 구현해야 합니다. (ex : 2PC, SAGA 패턴 등)
그렇다면 NoSQL인 Redis도 트랜잭션을 지원할까요?
바로 위의 (2) 확장성에서 아래와 같이 언급한 이력이 있다는 점을 기억해야 합니다.
반면 NoSQL인 Redis는 클러스터 구조를 통해 데이터를 여러 노드에 분산 저장할 수 있습니다.
클러스터 구조는 데이터를 여러 개의 Master 노드에 샤딩(분산 저장)하는 기법으로, 쓰기와 읽기 부하를 모두 분산하는 구조입니다.
클러스터 구조에서는 굳이 샤딩을 구현하지 않아도, 클라이언트가 특정 키를 해싱하여 적절한 노드에 요청을 보내는 방식이 이루어집니다. 클러스터 구조에 대해 디테일하게 설명되진 않았으나, 해당 구조에서는 여러 노드로 분산되어 저장이 가능한 것으로 해석이 됩니다.
조금 더 딥 하게 설명하자면, 클러스터 구조에서 key는 slot으로 관리가 되며 저장된 slot의 위치에 따라 어느 노드로 요청을 전달할지가 결정됩니다.
때문에 클러스터 구조에서는 key가 동일한 슬롯에 존재할 경우에만 트랜잭션이 지원되며, 만약 서로 다른 슬롯에 저장된 key로 트랜잭션을 구현할 경우,
아래와 같이 CROSSSLOT 에러가 발생합니다.

4. Redis의 특징
1. 디스크 X, 인메모리 O = 빠름
Redis의 특징을 논하면 RDB보다 성능 상에서 빠르다는 특징이 필시 언급됩니다.
때문에 특정 기간 동안의 이벤트나 과도하게 트래픽이 몰리는 서비스에서는 Redis를 필수로 사용하고는 합니다.
Redis가 빠르다고 평가되는 이유는 무엇일까요? 간략하게 아래와 같이 요약이 될 수 있습니다.
- Redis는 인메모리 DB이며, 주 메모리(RAM)에 데이터를 저장하고 관리
- 디스크에 접근하는 과정이 필요 없고 메모리에만 데이터를 저장하므로 초고속 처리 가능
- MySQL과 같은 온메모리 DB는 디스크에 데이터가 영구히 저장됨
- 자주 사용되는 데이터는 캐싱되어 메모리에 올라가는 경우도 있음
- 그렇지 않은 경우, 데이터를 찾고자 할 때 직접 디스크에서 데이터를 검색 후 페이지 단위로 메모리에 올려 데이터를 찾는 과정이 반복됨
인메모리 DB라서 빠르다는건 이해가 됐습니다.
그렇다면 디스크에 영구 보관 되지는 않는 것 같은데, 빠른 속도를 취한 대신 안정성은 트레이드 오프를 한 걸까요?
Redis의 데이터의 영속성(= 데이터가 메모리를 넘어 디스크에 저장되는 정도)과 관련해서, 레디스는 데이터를 AOF(Append Only File)와 RDB(Redis Database) 형식으로 디스크에 주기적으로 저장할 수 있습니다.
이로인해 Redis에 장애가 발생해 데이터가 유실되더라도 백업 파일을 이용하면 복구가 가능합니다.
추가로 Redis가 싱글 스레드라는 구조는 속도가 빠르다는 특징에 한 몫 차지합니다.
몇 차례나 언급된 싱글 스레드는 바로 아래 2. 싱글 스레드 파트에서 디테일하게 다뤄보도록 하겠습니다.
2. 싱글 스레드
분명 바로 위의 1번 소주제에서 싱글 스레드가 Redis의 빠른 속도라는 특징에 한 몫을 차지한다고는 했지만, 무언가 기묘합니다.
스레드가 많을 수록, 다시 말해 멀티 스레드일 수록 단 시간내에 동시 요청을 보다 빠르게, 많이 처리할 수 있을 것 같지만 Redis는 반대로 싱글 스레드라 빠른 속도를 보장한다고 합니다.
왜 그런 걸까요? 이와 관련하여 하나씩 분석해보겠습니다.
(1) Redis의 싱글 스레드 구조
- Redis는 싱글 스레드로 동작
- 메인 싱글 스레드 1개 + 별도 스레드 3개 = 총 4개
- 클라이언트로부터 전송된 네트워크를 읽는 부분과 전송하는 부분은 백그라운드의 별도 스레드에서 동작 (Redis 6 이상 버전부터 지원)
- 클라이언트의 커멘트를 처리하는 핵심 부분은 이벤트 루프를 이용한 싱글 스레드로 동작
- 따라서 최소 1개의 코어만 있어도 레디스를 사용할 수 있어 배포가 쉬움
- CPU가 적은 서버에서도 좋은 성능을 낼 수 있음
- 단, 싱글 스레드의 구조 특성상, 한 사용자가 오래 걸리는 커멘드를 실행하면, 다른 사용자는 해당 쿼리가 완료될 때 까지 대기해야 함
- ex : KEYS로 Redis에 존재하는 모든 key 값들을 조회
- 인메모리 DB이니 웬만하면 빠른 응답을 갖지만, 간혹 반환이 느린 커멘트도 존재하니 주의해야 함
(2) 멀티 스레드 vs 싱글 스레드
- 멀티 스레드일 경우 CPU에서 컨텍스트 스위칭, 스케쥴링, 스레드 생명주기 관리에 신경써야함
- 그러나 싱글 스레드는 위의 작업들을 신경써줄 필요가 없음 -> 오버헤드가 없음 -> 속도 향상에 집중 가능
- 예시로, 락(Lock) 없이 연산을 수행하므로 컨텍스트 스위칭 비용이 없음
멀티 스레드와는 달리, 싱글 스레드에서는 오버헤드가 없으므로 속도가 빠르다는 점을 이해했습니다.
이벤트 루프를 이용한 싱글 스레드로 인해 빠른 동작을 지원한다는 점이 포인트 같은데, 이 부분을 좀 더 분석해보겠습니다.
(3) 이벤트 루프와 I/O 멀티 플렉싱
- 여러 클라이언트가 요청을 보낼 때, 스레드 하나가 여러 개의 소켓을 감시하면서 요청이 준비된 경우만 처리하는 방식
- 리눅스에서 제공하는
epoll또는select같은 기술을 사용해서 비동기적으로 이벤트를 감지 - 일반적인 블로킹 서버 (스레드 1개 -> 요청 1개)
- 요청 1을 처리 중 -> CPU가 대기 (다른 요청을 못받음)
- 요청 1 완료 후 요청 2 처리 -> 순차적 실행 -> 느림
- Redis 방식 (이벤트 루프 + I/O 멀티 플렉싱)
- 요청 1을 받고 실행 (DB 조회 등으로 시간이 걸림)
- 그동안 요청 2를 받고 대기 (이전 작업이 끝나면 즉시 실행)
- 요청 1 완료 -> 즉시 요청 2 실행
- 요청 2 완료 -> 즉시 요청 3 실행
- 따라서 CPU가 놀지 않고 계속 처리할 수 있음
이제 상기 언급된 내용들을 정리하면 Redis의 싱글 스레드 구조가 왜 성능상 빠르다른 장점을 갖고있는지 아래와 같이 요약될 수 있습니다.
- 락(Lock) 없음 -> 컨텍스트 스위칭 비용 없음
- I/O 멀티 플렉싱 -> 여러 클라이언트의 요청을 비동기 처리
- (Redis 버전 6 부터) 네트워크 I/O는 백그라운드의 멀티 스레드에서 동작하고, 실제 명령 수행은 싱글 스레드(=메인 스레드)에서 실행
- 이벤트 루프가 준비된 요청을 빠르게 실행하기 때문에 동시처리가 가능한 것처럼 작동
- 고로 요청을 병렬로 처리하는 것은 아니지만, 대기 시간 최소화로 빠르게 응답할 수 있음
- 메모리 기반 연산 -> 디스크 I/O 없이 인메모리 DB에 저장하여 빠른 응답
3. 고가용성
만약 Redis에서 고가용성(HA, High Availability, 장애 없이 지속적으로 동작) 이 보장되지 않으면 어떤 일이 일어날까요?
아래와 같은 시나리오를 예상할 수 있습니다.
1. 마스터 서버에 장애 발생시, 복제본 노드에 접속하여 REPLICA OF NO ONE 커맨드를 입력해 읽기 전용 상태 해제
2. 어플리케이션 코드에서 레디스의 엔드 포인트를 복제본의 IP로 변경
3. 배포 트래픽이 많은 서비스에서는 위와 같은 방식으로 장애를 대응하다가는 유저의 서비스에 크리티컬한 임팩트를 끼칠 수 있습니다.
다행이도 Redis는 자체적으로 고가용성을 제공합니다.인메모리 DB에 데이터가 저장되는 Redis의 특징상 고가용성의 보장은 필수이기 때문입니다.
Redis에서 고가용성을 보장하는 방식으로는 Sentinel이라는 개념이 존재합니다.
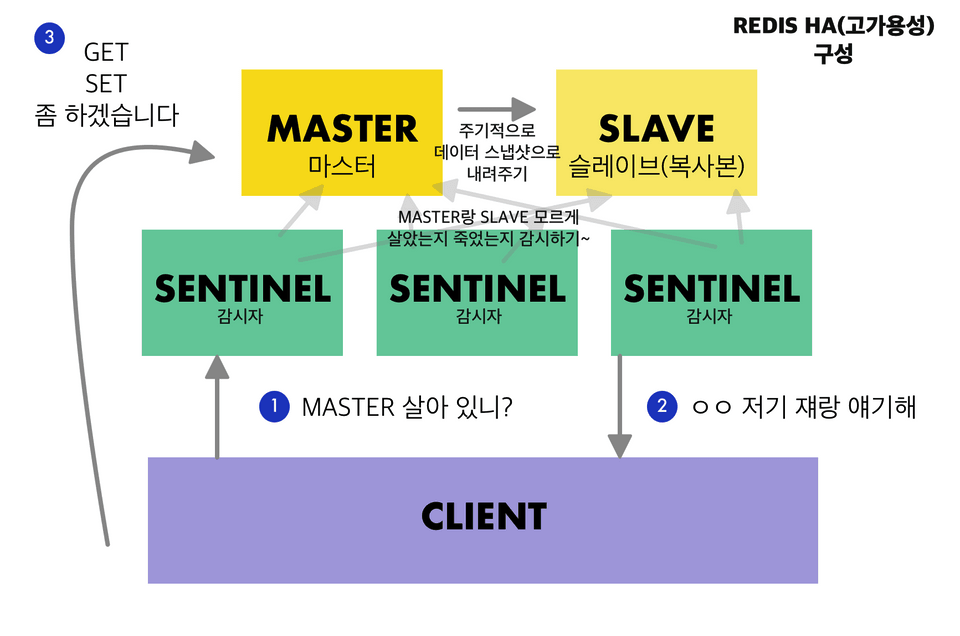
- 레디스의 자체 고가용성
- Master - Slave 구조에서 Master 장애 감지 & 자동 복구 가능
- Automatic Failover : Sentinel 프로세스가 Master를 감시 -> 장애 발생 시 Slave를 마스터로 승격
- 따라서 장애시 레디스의 엔드 포인트를 직접 바꿔줄 필요가 없음
- 읽기 부하 분산 가능 (Master에서 쓰기, Slave에서 읽기 수행)
- 하지만 쓰기 확장은 불가능 (하나의 Master에서만 가능)
이러한 Sentinel은 레디스의 다운타임을 최소화하도록 유도합니다.
Sentinel에 대한 디테일한 내용을 조금 추가하자면 아래와 같은 내용으로 정리가 됩니다.
• 센티널은 분산시스템으로 동작한다
SPOF(Single Point Of Failure)는 하나의 서비스에 문제가 발생했을 때 전체 시스템이 영향을 받는 지점 (= 문제의 원흉)- 복제와 자동 페일오버로 고가용성을 확보하는 이유는 레디스가 SPOF가 되는 것을 방지하기 위함
- 센티널은 그 자체로 SPOF가 되는 것을 방지하기 위해 최소 3대 이상일 때 정상적으로 동작할 수 있도록 설계됨
- 상기 이미지를 보면 센티널은 3대
- 하나의 센티널에서 이슈가 생겨도 다른 센티널이 바톤 터치로 업무 진행
- 오탐을 줄이기 위해 센티널은 쿼럼(Quorum)이라는 개념 사용
- 마스터가 비정상 동작을 한다는 것에 동의해야하는 센티널의 수
- 일반적으로 센티널이 3대면 쿼럼은 2이며, 최소 2대의 센티널이 동의해야 페일오버 프로세스 수행
- 쿼럼은 보통 홀수로 구성 (무승부를 막기 위함)
5. 기타
이번 챕터에서는 저 처럼 Redis의 개념에 처음 접근하는 개발자를 위해 보다 원초적인 개념들에 초점을 맞추어 서술을 진행했습니다.
보다 많은 이야기를 다루고 싶었지만, TL;DR을 방지하기 위해 최소한의 핵심 내용만 서술하는 방향을 목표했습니다.
Redis를 공부하면서 특히나 싱글 스레드의 성능상 이점과 관련된 내용이 가장 인상 깊었는데,
이와 관련하여 참고 자료에 도움이 될 만한 레퍼런스를 기입했습니다.
아울러 내용 보충이 필요한 부분, 수정이 필요한 부분에 대한 피드백은 언제나 환영입니다! 🙆🏻♀️🙇🏻♀️
이번 챕터에서 다루지 못한 내용은, 추후 기회가 될때 다뤄볼 예정입니다.
대표적으로 아래 3가지 내용을 다루고 싶네요 😋
- 레디스로 캐시, 메시지 브로커, 분산 락 적용하기
- 레디스의 고가용성(센티널, 클러스터)은 어떻게 보장되는가
- 웹서비스 개발팀에서 업무를 진행하면서 Redis를 도입하면 좋겠다 싶은 부분
두서없이 장황했던 글을 읽어주셔서 감사합니다!
6. 참고 자료
'🖥️ CS > DB' 카테고리의 다른 글
| 복합 인덱스의 순서는 중요하다 (0) | 2025.01.06 |
|---|---|
| DB 데이터 동시성 이슈 해결법 (3) | 2024.11.13 |
| View 테이블 (2) | 2024.10.16 |